
interactive correlation map과 EDA 단계에서 interactive graph
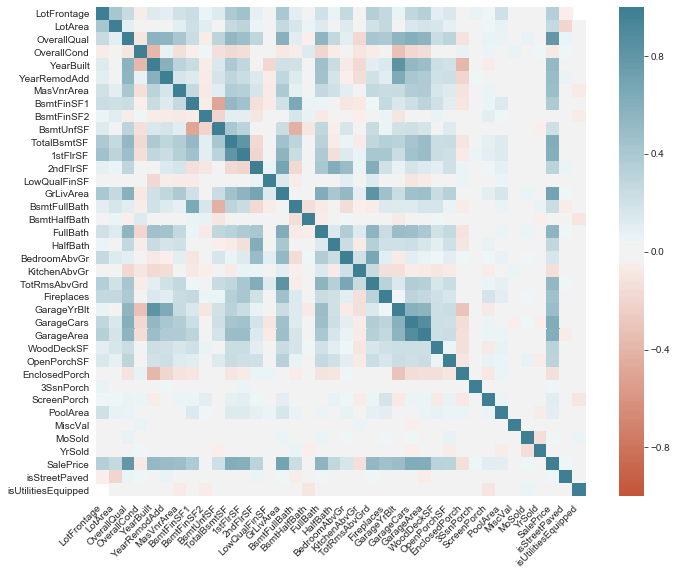
독립변수 간에 상관관계가 있는지 확인할 때 자주 그리는 히트맵이다. 왼쪽 아래의 짙은 빨간색은 EnclosedPorch랑 OverallQual 페어인가…? 절댓값으로 따지면 GarageYrBlt와 YearBuilt 페어보다 상관성이 강한 것이려나…? 이런 답답함을 한 번 쯤 느낀 적 있다면 plotly를 활용해서 인터랙티브 그래프를 그려보자!
독립변수는 독립적이어야 한다
우선 왜 이렇게 애써가면서 상관관계를 확인해야 하는지 간단히 짚고 넘어가자. 독립변수는 ‘독립’적이어야 한다. 그렇지 않고 독립 변수들 간에 상관성이 나타날 때 다중공선성이 존재한다고 말한다. 달리 말하자면 feature에 불필요한 중복이 있다는 것이다.
다중공선성은 회귀 모델에 특히 치명적이다. 회귀 모델은 기본적으로 각 독립변수가 한 단위 변화할 때 종속변수가 어떻게 변화하는지 알아내고자 하는 모델이며, 이 때 관심 있는 독립변수를 제외한 나머지 독립변수는 값이 고정되어 있는 상수로 취급한다. 그런데, 다중공선성이 존재하면 종속 관계에 있는 다른 변수가 고정된다는 것이 불가능하다.그러므로 feature들 간 상관계수를 확인하여 다중공선성을 제거해주는 것이 좋다
더 나은 히트맵을 향해서
상관계수를 확인할 때 단골처럼 등장하는 것이 히트맵이다. 그리드 형태로 이뤄진 히트맵의 특성상 쌍으로 이뤄진 값들의 대소를 한 눈에 비교할 수 있다는 강점이 있다. 아래처럼 코드 두 줄이면 히트맵이 뚝딱 나온다
corrMatrix = df.corr()
sns.heatmap(corrMatrix, annot=True)
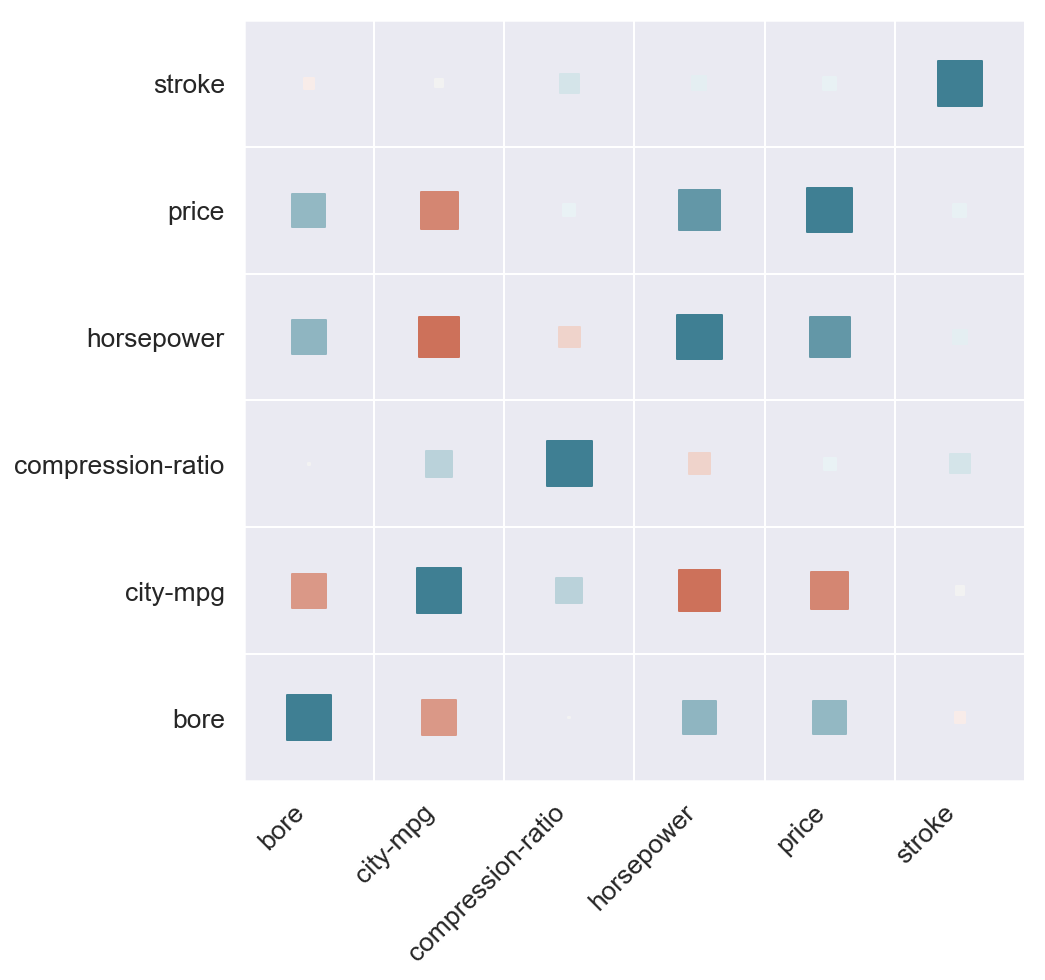
물론 보기 편한 히트맵을 그리려면 몇 가지 커스터마이징이 필요하다. 이 글에서는 아래 사진처럼 correlation matirx를 보다 효과적으로 시각화하는 방법을 제시하고 있다.
그런데 이러한 히트맵도 변수의 개수가 10개가 넘어가기 시작하면 한계에 부딪힌다. 첫번째로는 그리드에서 각 칸이 어느 변수와 어느 변수의 쌍인지 확인하기가 불편하다는 점이다. 모양 빠지게 손으로 짚어가면서 각 칸이 어느 변수에 해당하는지 확인할 수는 없지 않은가. 두번째는 크기나 색 등 연속적인 변화는 그 크기를 정확히 감별하고자 할 때 불편하다는 것이다. 특정한 threshold를 설정하고(예를 들면 0.5) 그 값보다 클 경우 다중공선성이 있는 것으로 판단하겠다는 기준이 미리 정해져 있다면 크게 불편하지 않을 수도 있다. 그 경우라면 히트맵이 아닌 다른 방법으로 변수쌍을 필터링 할 수 있다. 하지만 어떤 정보가 필요할지 조차 모르는 탐색적 시각화의 단계라면 히트맵이 더 많은 정보를 포함할수록 편리하다.
plotly 외안써?
그래서 plotly로 인터랙티브하게 구현해 본 히트맵. 마우스를 칸에 hover할 경우 해당하는 변수의 이름과 피어슨 상관계수가 텍스트 박스로 나타나며 Toggle Spike Lines 기능을 켜서 바로 x축과 y축으로 보조선을 내릴 수도 있다.
import plotly.express as px
import pandas as pd
corrmat = df.corr()
fig = px.imshow(corrmat, x = corrmat.index, y = corrmat.index,
zmin=-1, zmax=1,
color_continuous_scale=px.colors.diverging.RdBu,
color_continuous_midpoint=0)
fig.update_layout(autosize=False, width=size, height=size)
fig.update_xaxes(tickangle=45, tickfont={'size':9})
fig.update_yaxes(tickfont=dict(size=9))
fig.show()
사실 탐색적 시각화 단계에서 plotly와 인터랙티브 그래프가 널리 사용되지는 않는 듯 하다. 그 이유도 충분히 알 것 같다. 인터랙티브 그래프는 탐색하는 사람의 인사이트에 의해 좌우되므로 탐색 결과의 재생산성이 거의 보장되지 않고 정적인 형식이 전달과 확산에 용이하기도 하다. plotly가 다른 시각화 패키지 만큼 안정적이지 않은 것도 한 몫한다(예를 들면 jupyter notebook에서 plotly로 생성한 그래프는 저장이 되지 않는다).
그럼에도 불구하고 내가 인터랙티브 시각화를 (비교적) 애용하는 이유는, 탐색 단계에서는 어떤 정보를 필요로 할 지 미리 알 수 없기 때문이다. 전달하고자 하는 메시지를 시각적으로 보여주고자 하는 것이 아니라, 내가 데이터를 이해하고 다음 단계로 진행하기 위한 인사이트를 얻기 위한 경우라면 최대한 많은 정보를 하나의 그래프 안에 집어 넣는 것이 좋고, 그 수단이 plotly를 통한 인터랙티브 그래프였다. feature 간 상관 계수를 파악할 때에도 ‘종속적이다’의 기준값을 어디로 할 지, 유난히 종속관계가 많은 feature는 무엇인지, 모델의 직관성을 고려했을 때 배제하지 않아야할 feature는 무엇일지 등 단순히 ‘상관계수가 x 이상이면 둘 중 하나의 변수를 제거한다’ 이상으로 고려해야 할 것이 많다. 그 다층적인 고민을 위해서 인터랙티브 그래프는 충분히 시도해 볼만 하다고 생각한다.